DBSCAN聚类
基于密度的噪声应用空间聚类 (DBSCAN)
基于密度的噪声应用空间聚类 (DBSCAN) 是一种无监督的 ML 聚类算法。无监督的意思是它不使用预先标记的目标来聚类数据点。聚类是指试图将相似的数据点分组到人工确定的组或簇中。它可以替代 KMeans 和层次聚类等流行的聚类算法。
KMeans vs DBSCAN:
KMeans 尤其容易受到异常值的影响。当算法遍历质心时,在达到稳定性和收敛性之前,离群值对质心的移动方式有显著的影响。此外,KMeans 在集群大小和密度不同的情况下还存在数据精确聚类的问题。K-Means 只能应用球形簇,如果数据不是球形的,它的准确性就会受到影响。最后,KMeans 要求我们首先选择希望找到的集群的数量。下面是 KMeans 和 DBSCAN 如何聚类同一个数据集的示例。
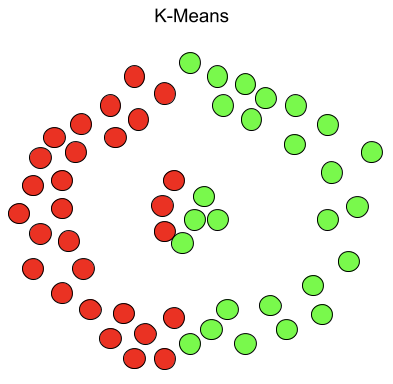
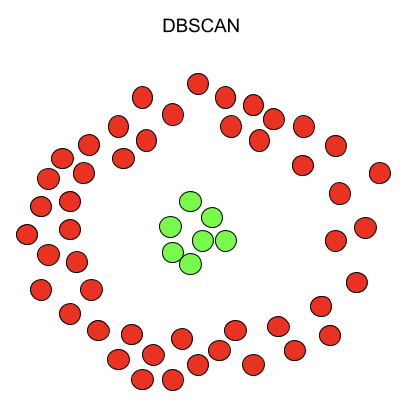
另一方面,DBSCAN 不要求我们指定集群的数量,避免了异常值,并且在任意形状和大小的集群中工作得非常好。它没有质心,聚类簇是通过将相邻的点连接在一起的过程形成的。
DBSCAN 是如何实现的呢?
首先,让我们定义 Epsilon 和最小点、应用 DBSCAN 算法时需要的两个参数以及一些额外的参数。
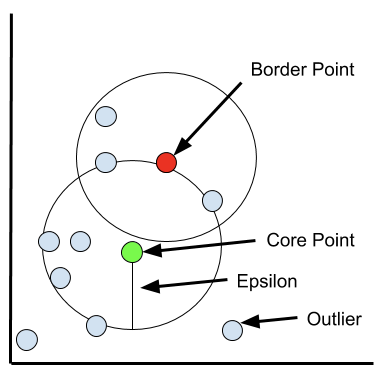
- **Epsilon (ɛ):**社区的最大半径。如果数据点的相互距离小于或等于指定的 epsilon,那么它们将是同一类的。换句话说,它是 DBSCAN 用来确定两个点是否相似和属于同一类的距离。更大的 epsilon 将产生更大的簇 (包含更多的数据点),更小的 epsilon 将构建更小的簇。一般来说,我们喜欢较小的值是因为我们只需要很小一部分的数据点在彼此之间的距离内。但是如果太小,您会将集群分割的越来越小。
- **最小点 (minPts):**在一个邻域的半径内 minPts 数的邻域被认为是一个簇。请记住,初始点包含在 minPts 中。一个较低的 minPts 帮助算法建立更多的集群与更多的噪声或离群值。较高的 minPts 将确保更健壮的集群,但如果集群太大,较小的集群将被合并到较大的集群中。
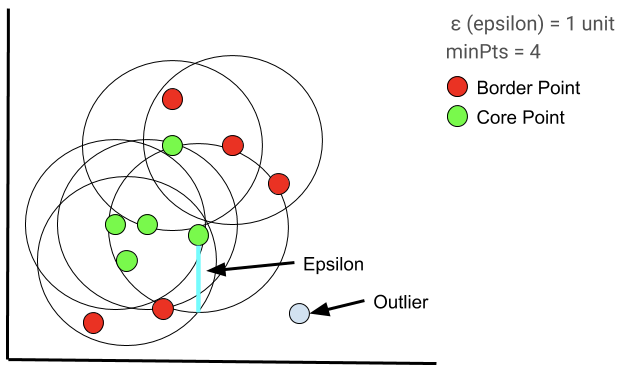
如果 “最小点”= 4,则在彼此距离内的任意 4 个或 4 个以上的点都被认为是一个簇。
其他参数:
核心点: 核心数据点在其近邻距离内至少有的最小的数据点个数。
我一直认为 DBSCAN 需要一个名为 “core_min” 的第三个参数,它将确定一个邻域点簇被认为是聚类簇之前的最小核心点数量。
边界点: 边界数据点位于郊区,就像它们属于近邻点一样。(比如 w / 在 epsilon 距离内的核心点),但需要小于 minPts。
离群点: 这些点不是近邻点,也不是边界点。这些点位于低密度地区。
首先,选择一个在其半径内至少有 minPts 的随机点。然后对核心点的邻域内的每个点进行评估,以确定它是否在 epsilon 距离内有 minPts (minPts 包括点本身)。如果该点满足 minPts 标准,它将成为另一个核心点,集群将扩展。如果一个点不满足 minPts 标准,它成为边界点。随着过程的继续,算法开始发展成为核心点 “a” 是“b”的邻居,而 “b” 又是 “c” 的邻居,以此类推。当集群被边界点包围时,这个聚类簇已经搜索完全,因为在距离内没有更多的点。选择一个新的随机点,并重复该过程以识别下一个簇。
DBSCAN的优点
- 不需要像KMeans那样预先确定集群的数量
- 对异常值不敏感
- 能将高密度数据分离成小集群
- 可以聚类非线性关系(聚类为任意形状)
DBSCAN的缺点
- 很难在不同密度的数据中识别集群
- DBSCAN 算法的运行速度要比 KMeans 算法慢一些
- DBSCAN 算法的两个参数也是要根据具体的数据情况进行多次尝试。
o3d程序示例
import open3d as o3d
import numpy as np
from matplotlib import pyplot as plt
pcd = o3d.io.read_point_cloud("test_data/fragment.ply")
# 距离0.05,最小点数量10
with o3d.utility.VerbosityContextManager(
o3d.utility.VerbosityLevel.Debug) as cm:
labels = np.array(
pcd.cluster_dbscan(eps=0.05, min_points=10, print_progress=True))
max_label = labels.max()
print(f"point cloud has {max_label + 1} clusters")
colors = plt.get_cmap("tab20")(labels / (max_label if max_label > 0 else 1))
colors[labels < 0] = 0
pcd.colors = o3d.utility.Vector3dVector(colors[:, :3])
o3d.visualization.draw_geometries([pcd],
zoom=0.455,
front=[-0.4999, -0.1659, -0.8499],
lookat=[2.1813, 2.0619, 2.0999],
up=[0.1204, -0.9852, 0.1215])