深度学习基础概要
[TOC]
Reference
李宏毅2022课程主页,课程B站链接,课程github(全是作业)
反向传播 Back Propagation
反向传播是一种用来计算执行梯度下降的算法。包含Foward Pass 和 Backward Pass两个步骤。
network的所有参数为$\theta=\left{w_{1}, w_{2}, \cdots, b_{1}, b_{2}, \cdots\right}$,需要计算每一个参数的梯度,即进行偏微分。
这里以某一权重为例计算$\partial C / \partial w$。针对下面偏微分的展开,分别分为Forward pass和Backward pass。
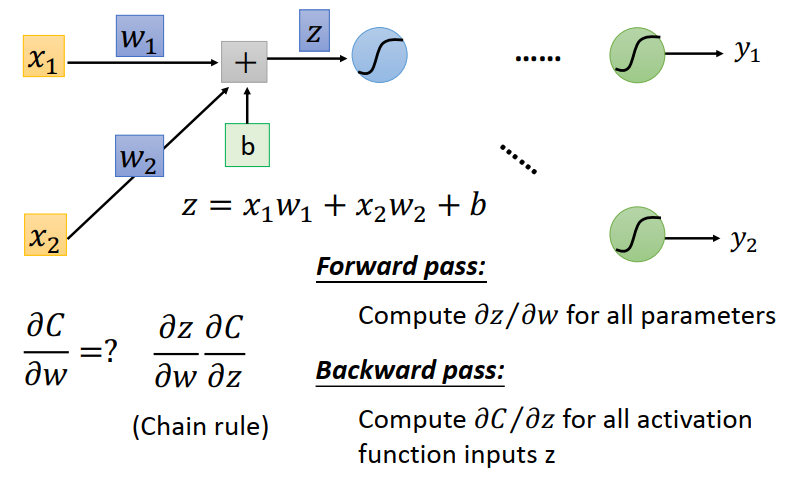
Forward pass
计算$\partial z / \partial w$,很明显等于当前层的输入:
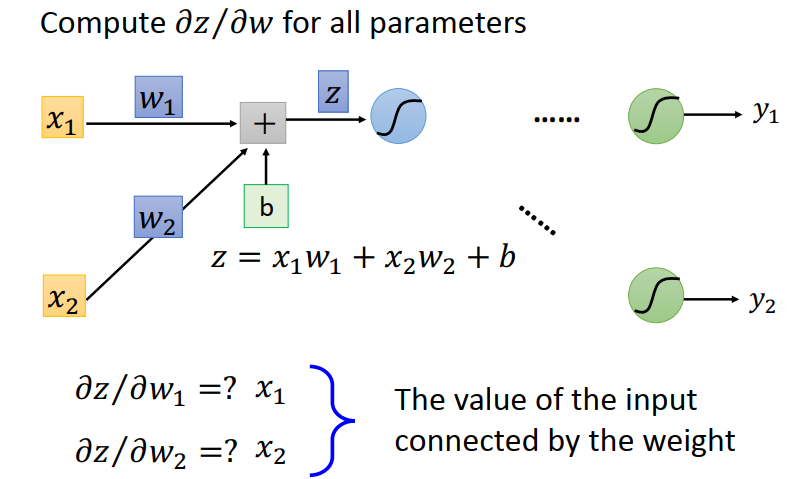
Backward pass
计算$\partial C / \partial z$,该计算依赖下一层的值,正向无法立刻计算出来,使用反向递推。
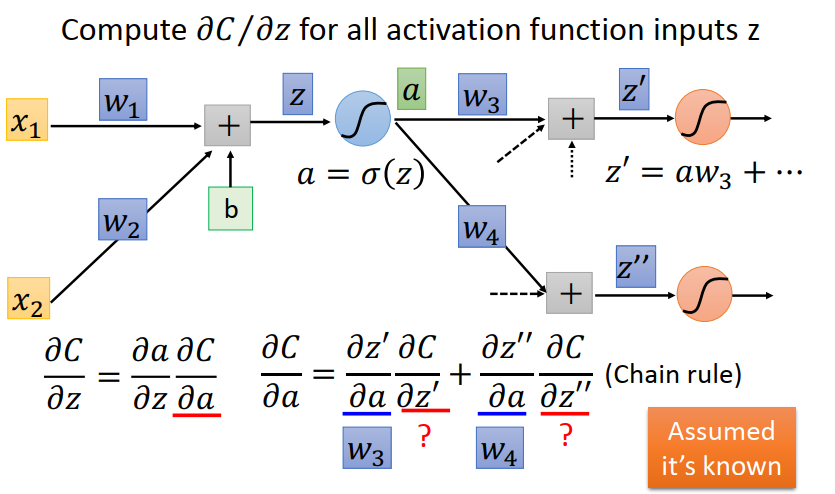
其中:$\partial a / \partial c$等于激活函数的倒数,是已知的,不用管。可以得出递推公式: $$ \frac{\partial C}{\partial z}=\sigma^{\prime}(z)\left[w_{3} \frac{\partial C}{\partial z^{\prime}}+w_{4} \frac{\partial C}{\partial z^{\prime \prime}}\right] $$ 所以一个求偏导的过程就变成了:
- 正向前进时,记住每一层的input。
- 反向前进时,递推计算$\partial C / \partial z$直到当前参数所在层。
- 再乘以正向时保存的$\partial z / \partial w$值,得到最终偏导。
Optimization
reference:李宏毅2021-Batch and Momentum、Adaptive Learning Rate
如何避免critical points(局部最小,鞍点)? batch && Momentum
batch
“Noisy” update is better for training
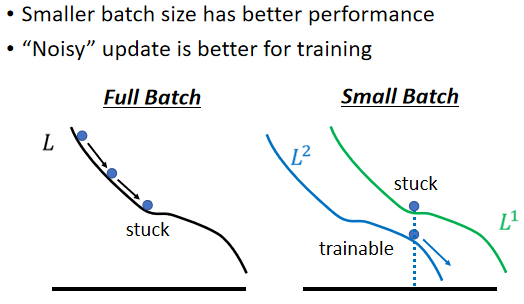
由于每一个batch的样本都是有差异的,所以计算出的loss和loss function都是有差异的,即时上一个batch真的陷入了critical point,梯度为0没有更新,下一个batch进来时,如上图它很可能就不会卡住。
Momentum
看下图公式,加入momentum的变化。
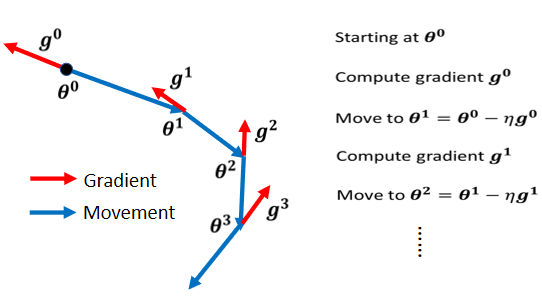
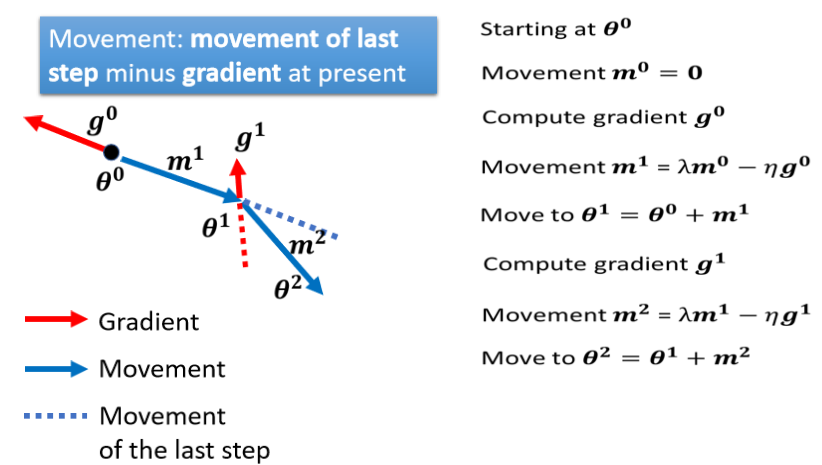
Momentum 在,Gradient 的负方向加上前一次移动的方向。但是上一次移动的方向也会再考虑上上次的方向,所以momentum考虑了过去所有 Gradient 的总合。
作用示意:
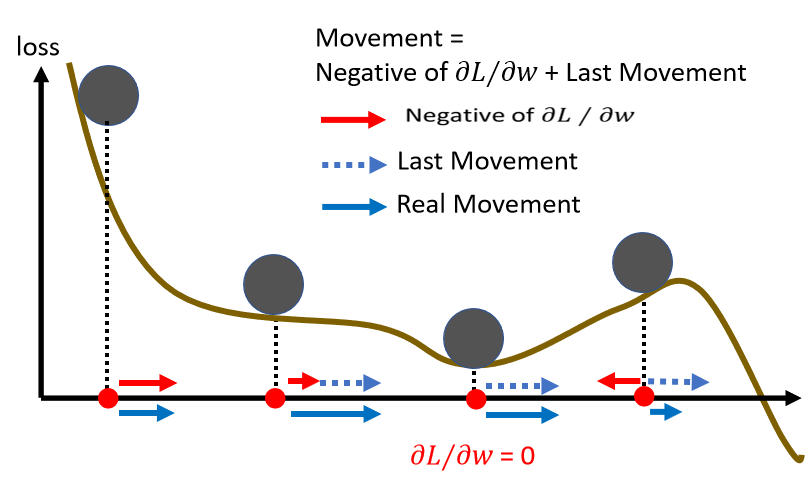
上图local minima处,即时当前梯度为0了,在momentum的作用下依然向右运动;在最后一个point处即使梯度要救向左运动了,在之前累积的梯度作用下,依然最后是向右运动的,所以可以帮助越过局部最小值。当然如果最后一点右侧这个峰足够高,以至于可以中和之前正向的梯度,那么函数还是会跌回山谷(局部最优)。
Adaptive Learning Rate 自动调节
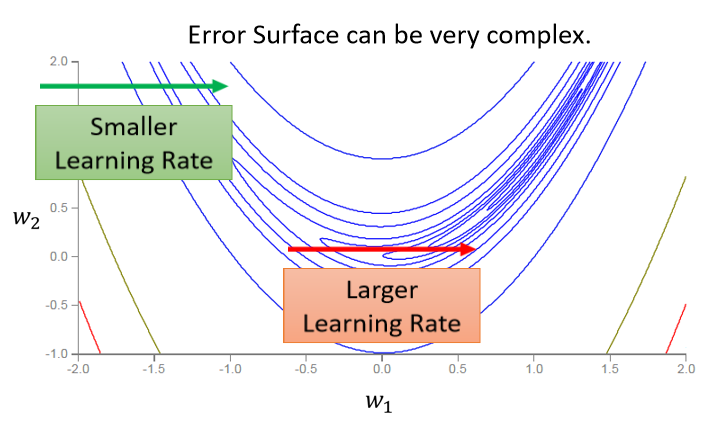
很多时候如果网络训练不动了,loss不再下降,其实并不是因为训练完了或者走到了critical point。有实验表明,其实走到critical point的概率很低,大多数时候训练不动了是因为learning rate太大,loss在来回震荡。如下图示意,此时梯度并不等于0,loss在谷间震荡。
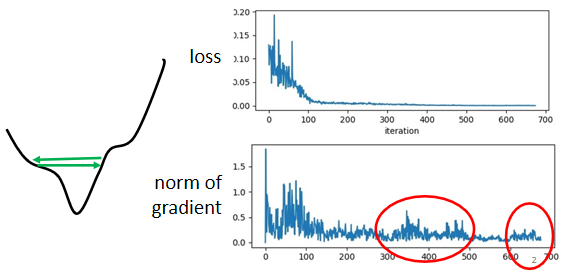
所以我们需要在跟据具体情况调整学习率,中和梯度的改变。所以有了RMS(均方根)的思路:
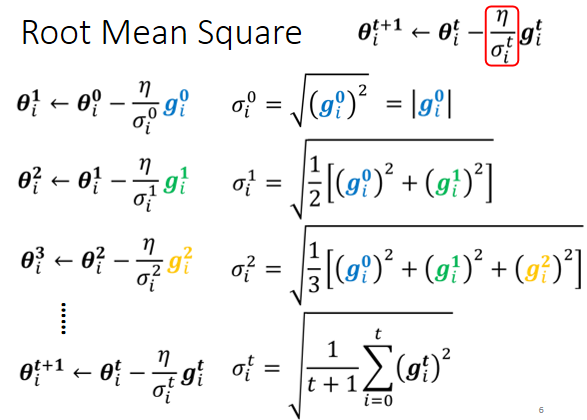
基础思路是让学习率除以一个于梯度正相关的值,梯度越大,则整体学习率越小;梯度越小,则整体学习率越大。至于为何引入均方根呢?我的想法是引入全局信息可以防止因为某一次梯度太大或者太小引起的异动。
但是呢,你会发现,现在${σᵢ}$只与梯度值的均方根有关,所以这个学习率相对来说会比较稳定,但是万一随着参数的不断改变,梯度值在某块区域跟之前存在较大差异,这时就需要考虑${σ}$之间的关系了。
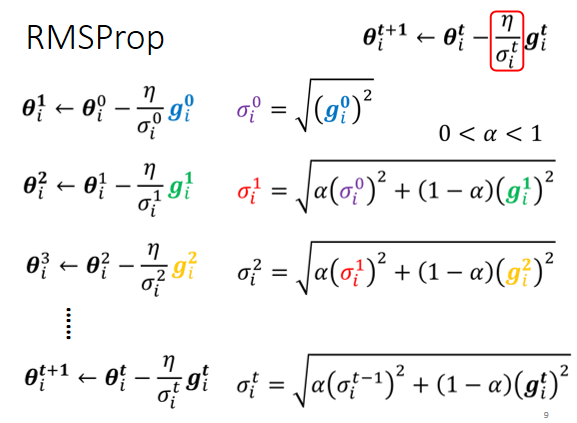
RMSProp引入超参数控制${σ}$于梯度的比例。可以比较自由的决定附近学习率于当前梯度的重要程度。
Adam
如今最常用的optimizer是Adam=RMSProp+Momentum。pytorch已经实现了该优化器并且预设了一些超参数,通常不需要我们自己调整。
Batch normalization
”之前才讲过说,我们能不能够直接改error surface 的 landscape,我们觉得说 error surface 如果很崎嶇的时候,它比较难 train,那我们能不能够直接把山剷平,让它变得比较好 train 呢?“
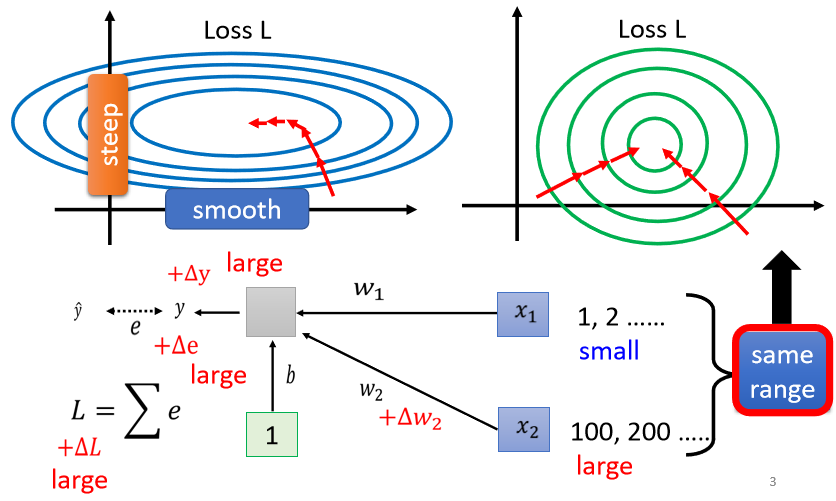
如果我们可以给不同的 dimension,同样的数值范围的话,那我们可能就可以制造比较好的 error surface,让 training 变得比较容易一点。有很多不同的方法实现这个目的,统称为Feature Normalization。这里要展开的是对batch进行操作,成为batch normalization(因为一个batch对应一次update,所以在batch上做norm效果会比较好,个人理解)。
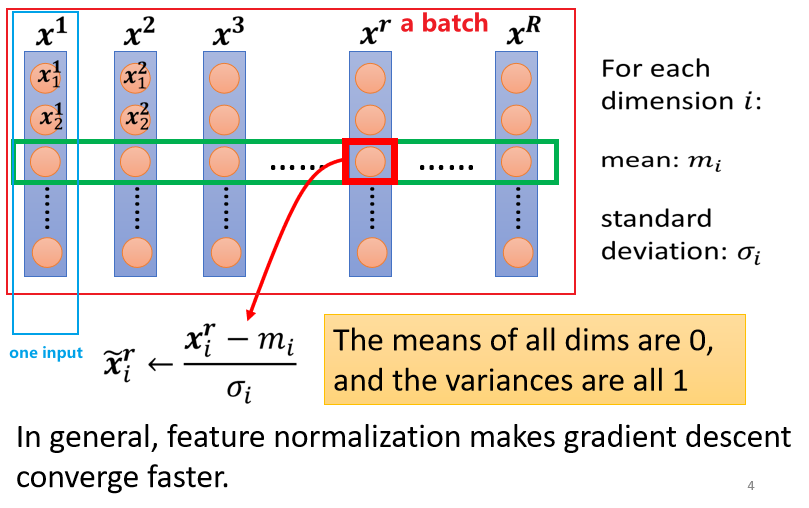
-
做完 normalize 以后啊,这个 dimension 上面的数值就会平均是 0,然后它的 variance就会是 1,所以这一排数值的分布就都会在 0 上下
-
对每一个 dimension都做一样的 normalization,就会发现所有 feature 不同 dimension 的数值都在 0 上下,那你可能就可以制造一个,比较好的 error surface
pytorch与项目结构简介
参考PDF:李宏毅2022 Pytorch Tutorial 1 。以下内容为PDF简化。
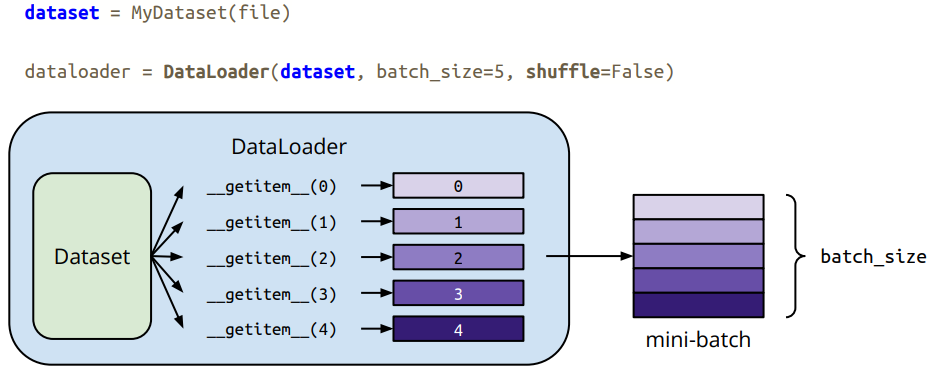
Dataset & Dataloader
dataset:存放数据与ground truth;Dataloader:将数据与真值按照批量大小分组,允许多线程。

自定义dataset需要重写下面两个关键函数:

最简示例:dataloader的返回值通常为(x,y),x的shape为,eg: [128 , 1, 224, 224],此为224X224的灰度图,batch size为128
model
定义网络架构,在forward内从前往后执行网络的架构。
一般会存放在model.py或者<网络名称>.py内。

loss
看任务类型,典型的:回归均方误差,分类交叉熵,点云一些应用使用chamfer loss(与最近点距离)。

optimizer
定义优化器(算法),当然最简单的是仅仅梯度下降,但现在基本都用的是torch.optim.Adam()。

train validation & test
现在很多地方不会明显区分validation与test,需要自己根据语境去判断说的是什么意思。
training跟validation都是需要ground truth的,是要计算loss的,即通常说的把一个数据集分为训练集和测试集,这里的测试指的是validation。train要更新梯度来更新参数,validation不更新。
而test是没有ground truth的,所以也不存在计算loss一说,即你随便拿一些数据过来测试你训练的模型的效果。
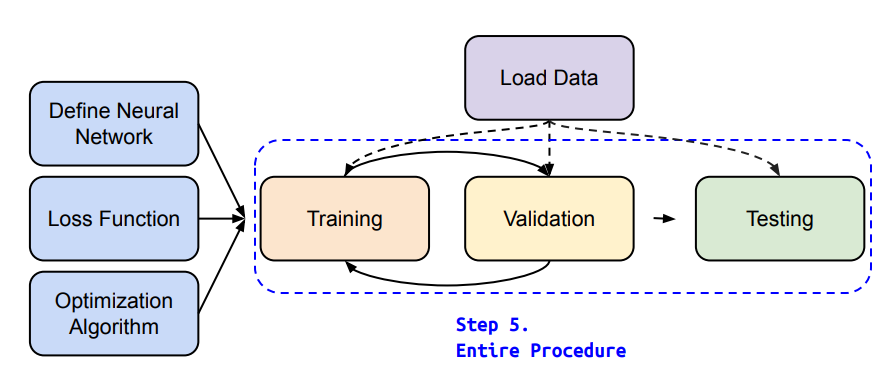
- 看一下三种流程的pytorch流程:
切换train和eval的目的是,有些方法在train和eval中表现不一致,比如drop out 和batch norm。
