深度学习点云配准
使用深度学习处理点云
数据集
| name | 备注 | 常用于 |
|---|---|---|
| ModelNet | CAD模型生成 | 分类 |
| KITTI、nuScenes、WOD | 自动驾驶数据集 | 3D物体检测 |
| 3D Match | RGBD拼接点云,来源与同名论文 | 生成特征描述子 |
基础框架
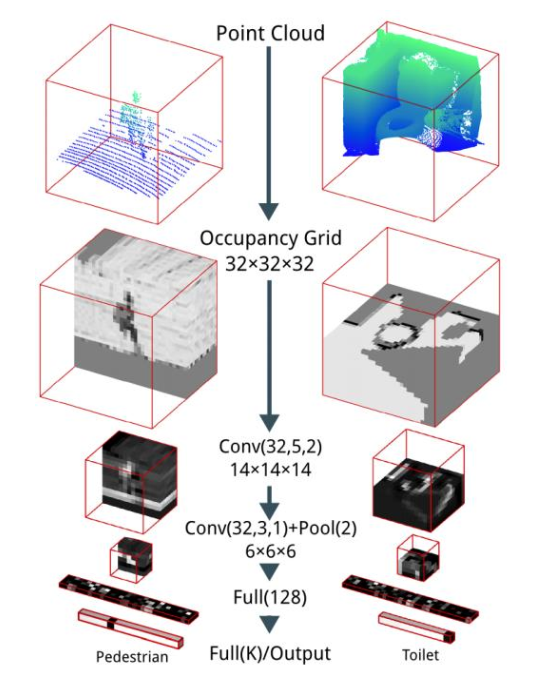
VoxNet, IROS 2015 2400
PDF, author VoxNet: A 3D Convolutional Neural Network for Real-Time Object Recognition
基于体素处理点云,类似处理二维的图像,在voxel上面进行三维卷积操作。(二维卷像素,三维卷体素)
卷积+pool,将feature map处理到较小尺寸,然后拉直
PointNet, CVPR 2017 7200
Charles Ruizhongtai Qi, PDF, video
作者在video中提到如今三维点云的处理方式依旧是沿用2D的卷积类型,有没有直接作用在点云上特征学习网络呢。
基于点处理点云
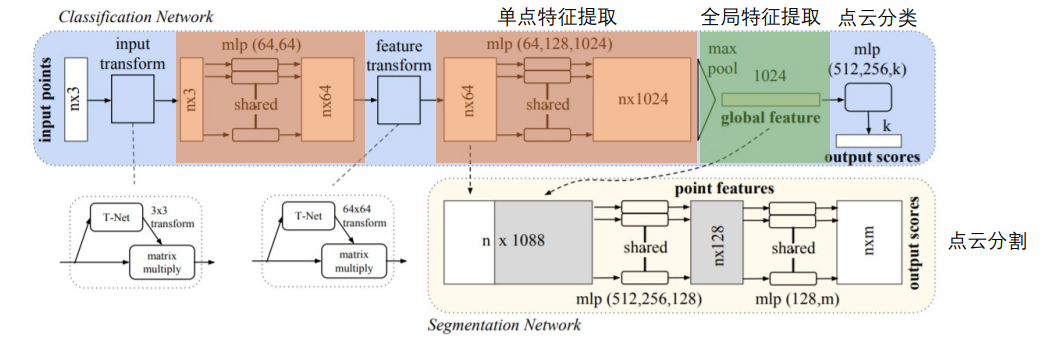
core idea : max pool。忽略transform部分,后续研究证明没用。shared MLP + max pool
输入点云,经过多层全连接层并max pool后可以得到该输入点云的global feature。这一点至关重要。
分类任务:
直接使用全连接将1024降到k维。(k为类别)
语义分割:
将1024的全局特征叠加到每个64维的单点特征上,得到NX1088的特征矩阵,包含了局部和全局的信息,再使用全连接输出为nXm的shape。m为类别。
解决乱序输入的问题:
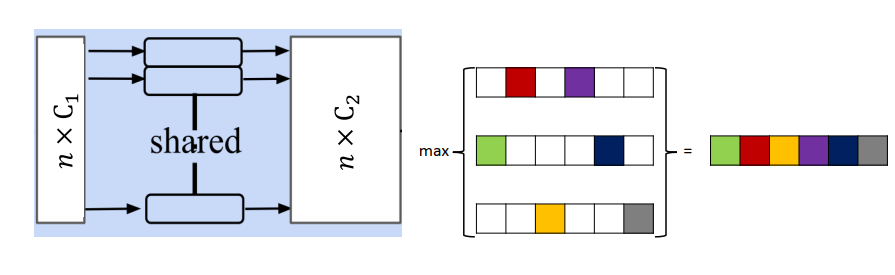
不管点云内输入的顺序是怎样的(即交换上图行的位置),经过max pool后,结果都是一样的!
缺点:
缺少分层的特征聚合(Lack of hierarchical feature aggregation),没有向2D卷积提出的金字塔结构一般的感知域。
PointNet++ 2017 4700
总体框架
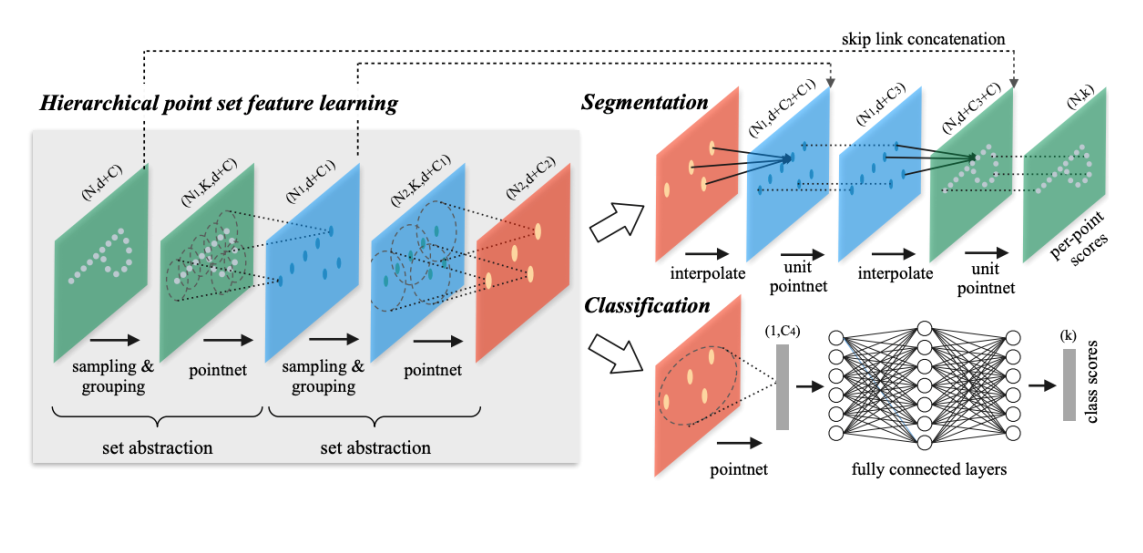
core idea: Hierarchical point set feature learning, 分层的点集特征学习
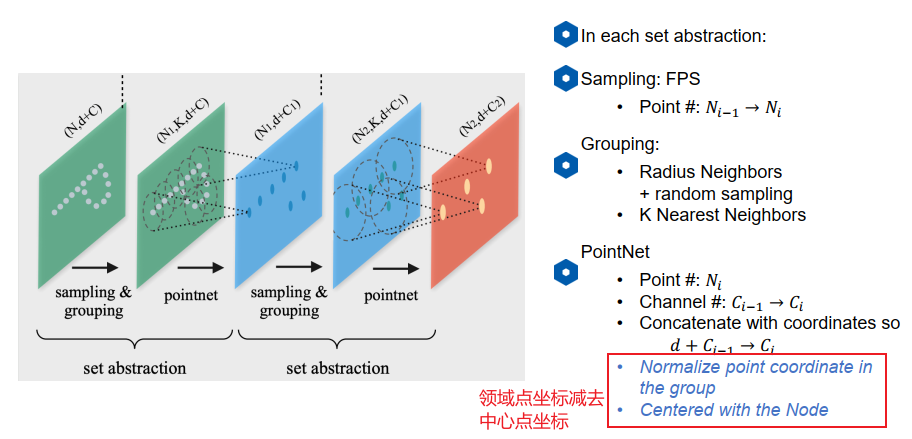
一次set abstraction的流程:
- 采样(最远点采样)
- 分组:可以使用knn或者半径阈值+随机采样。因为要保证输入的数量相同,所以需要的基于半径的方式随机采样。
- 将k个点输入pointnet得到该点集的特征向量,局部的"global feature"。输入N1组,每组K个点,点的channel包含三维坐标和一些额外特征C,比如法向量。
数据增广trick:
DP数据预处理手段。(随机将样本降采样到100-5000个点)
加噪声
加旋转
深度学习特征点云配准
做特征提取的少(对于特征的定义不绝对,如何判断检测出来的点是特征点?),做特征描述的多(方便训练,可以检验描述子是否有效)。
特征点提取
USIP, ICCV 2019, 60
点云特征点提取网络。
两个idea:
- 特征点从哪看都是特征点,旋转平移不变
- 特征点跟尺度大小有关(感受域)
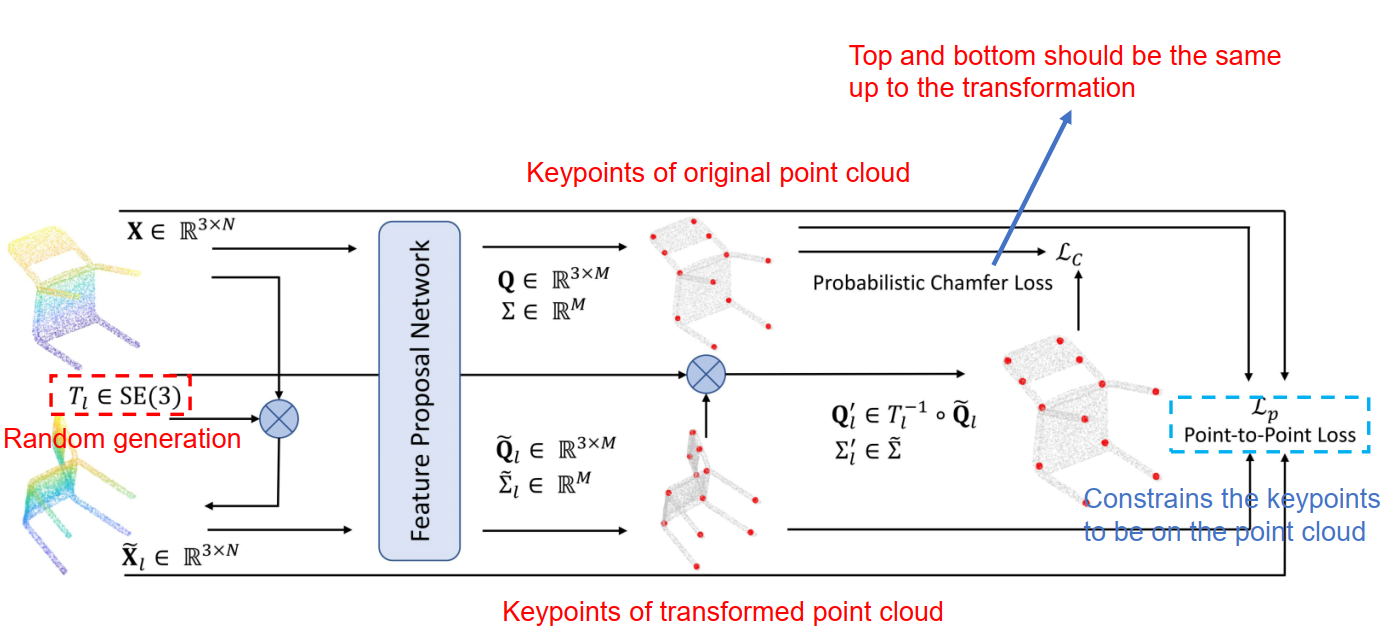
How to train?两个loss:
- 输入点云,产生特征点集1,将输入点云随机旋转后再次输入网络得到特征点集2,令点集2与点集1相等。
- 使产生的特征点集与原点云的距离尽量小。
特征描述
局部描述子。起到FPFH、SHOT等描述子的作用:输入局部的点集,生成特征向量。
**传统描述子的问题:**用传统描述子做特征匹配误匹配比较高,效果不是很好,提升空间还比较大。是否可以用深度学习生成更高维、更抽象的描述子呢?
3D Match, CVPR 2017 500
voxel based;一直进行卷积层,最后输出512维向量。
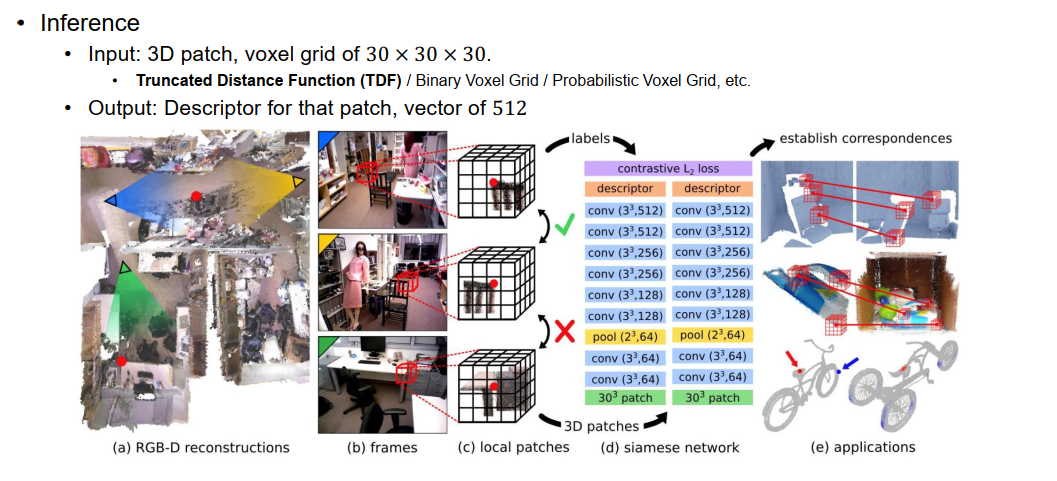
How to train?
contrastive loss.选取不同视角的同一点(<指定值)为中心的两个patch,由于是同一点,即使输出的descriptor相同。不同点则使descriptor不同。
loss function: 令positive接近0,令negative大于tao。

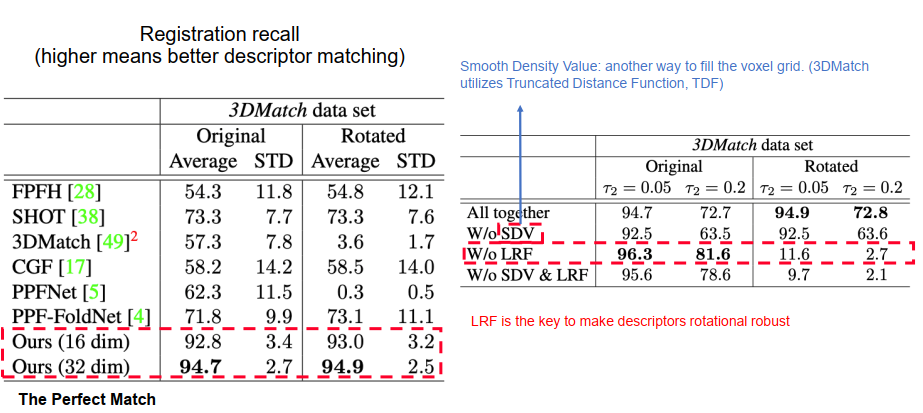
3DSmoothNet, CVPR 2019 190
PDF, author, github 350, The Perfect Match: 3D Point Cloud Matching With Smoothed Densities
voxel based
改进3D Match:
- 引入LRF决解旋转问题(Local Reference frame,局部参考坐标系)(类似SHOT描述子,使用PCA求三个主方向)
- 改进loss function
PPFNET, CVPR 2018 280
PDF, Haowen Deng,video at 1:04:48 PPFNet: Global Context Aware Local Features for Robust 3D Point Matching
Point based. Point pair featrue network.很经典的思路,对n个局部特征使用max pool得到全局特征,再将全局特征contact到局部特征上。
输入的得PPF是点坐标+<距离,三个角度>。输入两帧数据,每一帧有N个patch。
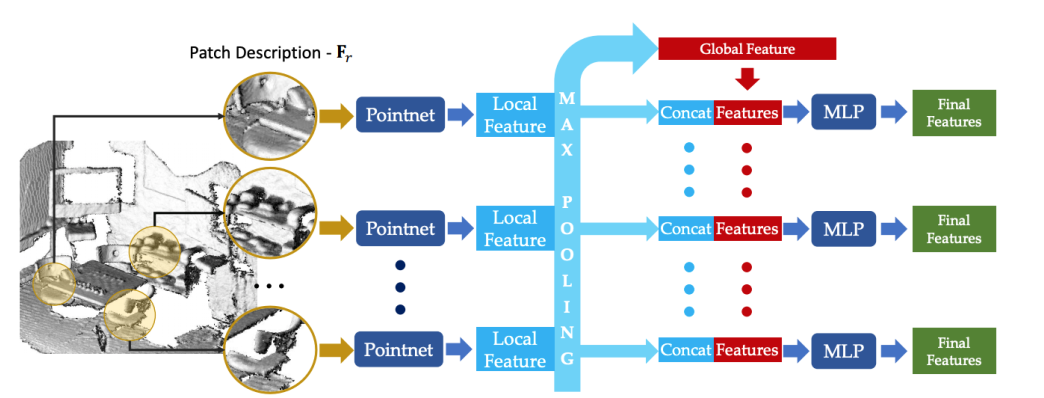
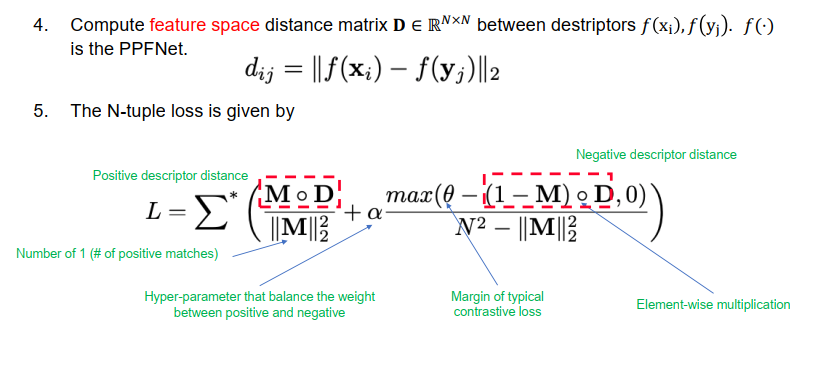
How to train?(输入为2N个patch,2 frame各N patch)
n-tuple loss. 其中,M为只包含0,1的mark(NXN),是一个corresponding matrix,描述xi和yj是否是对应点。D矩阵也是NXN,描述的是网络输出即特征空间的距离。

PDF, PPF-FoldNet: Unsupervised Learning of Rotation Invariant 3D Local Descriptors
原作者借鉴了同年CVPR的FoldNet迅速又发了一篇ECCV
预测的话就只使用encoder得到descriptor即可。
**注:**输入的4D PPF没有坐标信息,只有相对的距离和角度,类似FPFH,解决PPF-NET无法应对旋转问题(因为输入含有坐标信息)。
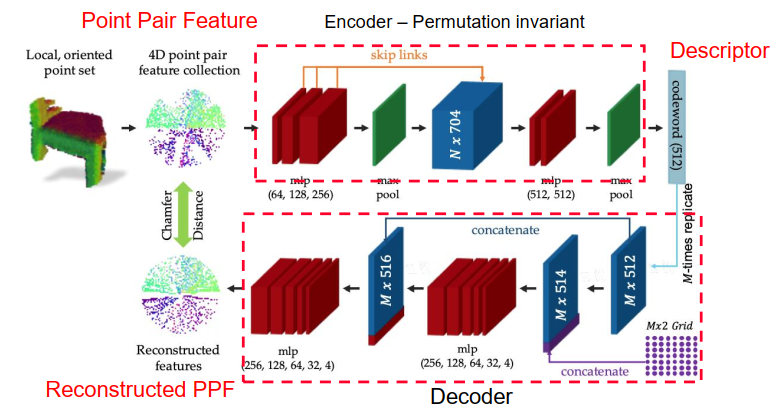
How to train?
无监督思路
训练思路很简单,输入4D的point pair feature通过encoder变成descriptor,然后再通过decoder变换回去,使两组PPF相等。
Time
3DMatch benchmark
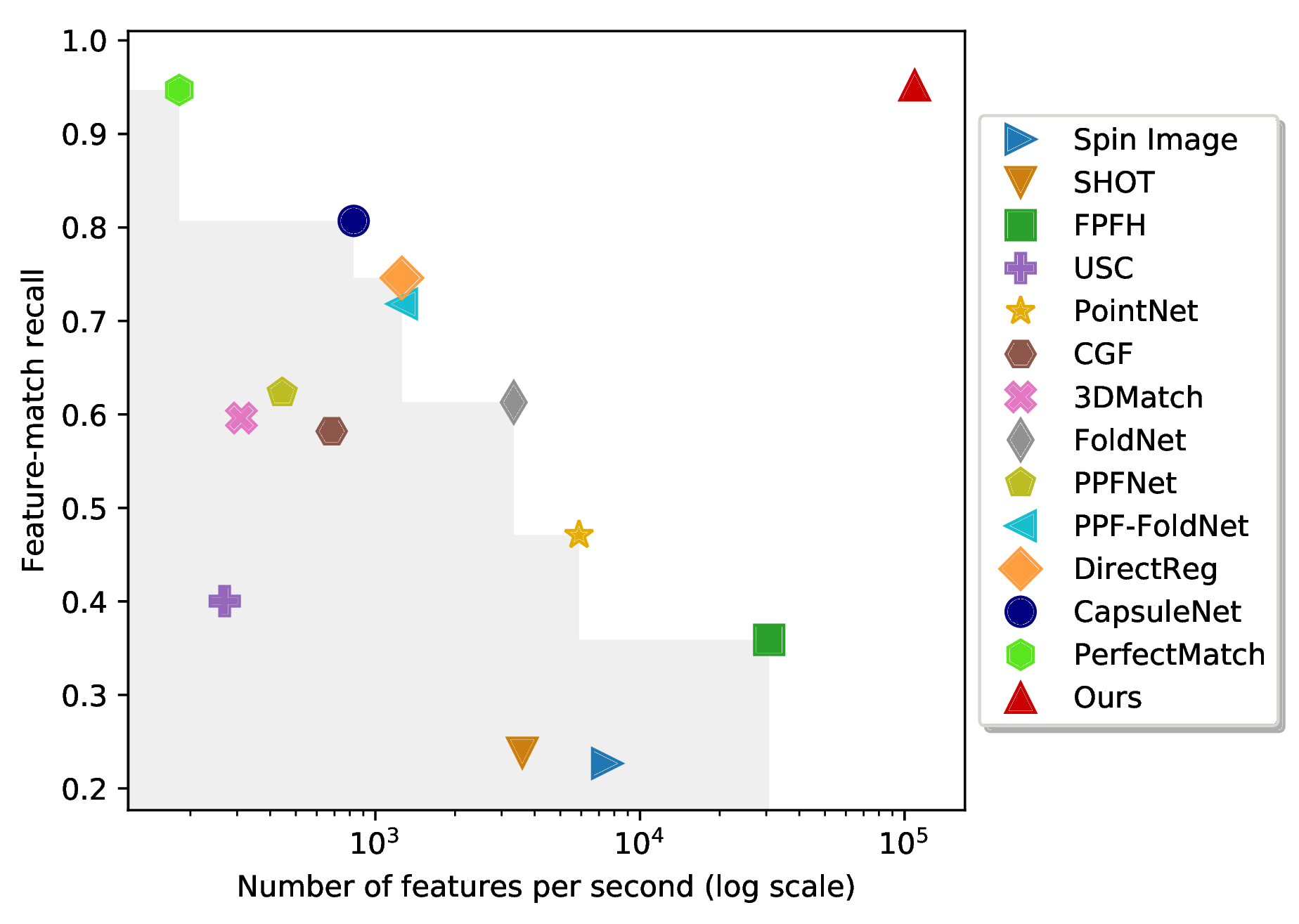
Reference
斯坦福大学在读博士生祁芮中台:点云上的深度学习及其在三维场景理解中的应用: https://www.youtube.com/watch?v=Ew24Rac8eYE
3D Match dataset : https://paperswithcode.com/dataset/3dmatch
awesome-point-cloud-registration: https://github.com/XuyangBai/awesome-point-cloud-registration
Xuyang BAI 白旭阳(港科技博士): https://xuyangbai.github.io/
Jiaxin(新加坡国立博士): https://www.jiaxinli.me/
FCGF: https://github.com/chrischoy/FCGF
深度学习点云匹配CSDN博客: https://blog.csdn.net/xckkcxxck/category_8468359.html
国内外点云处理著名的研究小组和学者: https://github.com/dongzhenwhu/Research-Groups-of-Point-Cloud-Processing
stargazer of YOHO: https://github.com/HpWang-whu/YOHO/stargazers
**排名:**Point Cloud Registration on 3DMatch Benchmark: https://paperswithcode.com/sota/point-cloud-registration-on-3dmatch-benchmark?p=generalisable-and-distinctive-3d-local-deep