深度学习物体检测
2D
Reference
-
教学视频与文档
-
三维点云处理技术,深蓝学院,Lecture 6-3D Obeject detection,PDF
-
cs231n, Detection and Segmentation(19年密歇根拓展版 lecture 15&16)。slides,b站视频包含17年斯坦福以及19年密歇根
-
讲得最细,不用看17版cs231n了:cs231n 密歇根2019,pages, lecture 15-object detection PDF,b站链接就在上面。
-
代码与结构剖析
-
一文读懂Faster RCNN:里面也包含了代码讲解
-
https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/tree/master/pytorch_object_detection:一个图像检测库,可以直接跑训练和测试,代码是torch官方代码加注释,虽然不是最新代码,但是几乎一样。
-
https://github.com/open-mmlab/mmdetection/blob/master/docs/zh_cn/article.md:mmdetection教程与实战。(讲得也比较详细)
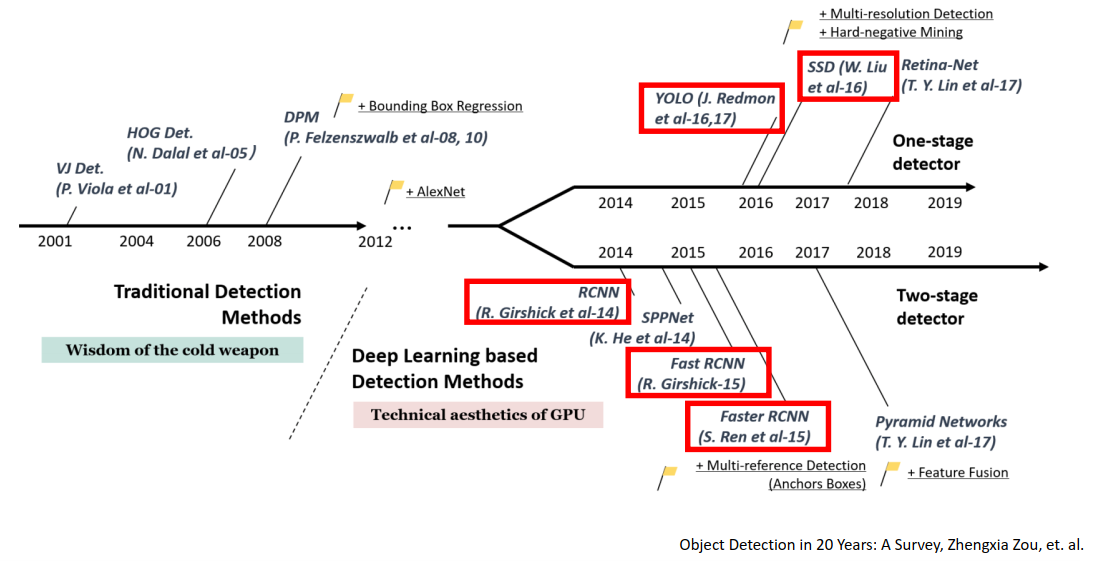
物体检测里程
图源见下标,这篇论文也被CS231n提到。
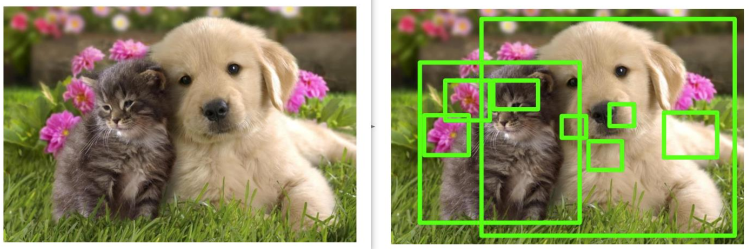
检测=定位+分类
引用参考 截至2022-04
| name | year | cition |
|---|---|---|
| r-cnn | 2014 CVPR | 2.4W |
| Fast r-cnn | 2015 CVPR | 1.9W |
| ResNet | 2016 CVPR | 11W |
| Mask r-cnn | 2017 CVPR | 1.8W |
CNN处理图像输入一个feature map(H X W X C),现在都喜欢这么干,在感受域不断变大的过程中,H、W不断变小。通常CNN是块结构,包含标准的卷积操作、max pool、resnet结构。
two stage
深度学习物体检测的基础是我们已经掌握了深度学习图像识别问题。
所以一种可能的物体检测思路是:在原始图像上通过一些方法框选出一部分区域(该方法称为region proposal),直接丢给识别网络,就能实现物体检测。框选取(region proposal)的策略中,一个简单而暴力的方法就是——使用滑动窗口,使用不同大小的窗口从左上滑倒右下,对每一个窗口都塞进网络进行一次分类识别。
显然这种方法是很耗时,就是最简单暴力法,目标物体的数量、位置、大小(比例)在图中都是未知的,暴力滑动窗口的步幅和框大小等都需要调整,也因此会产生巨量的框。

来看看怎样一步步改进。
RCNN
RCNN就是提出了一种region proposal的方法(非深度学习,selective search,原理是颜色聚类)来生成候选框,大概每张图像生成2k个候选框,然后再将候选框resize到统一大小丢尽网络,一个head做分类,一个head做x,y,w,h的回归。
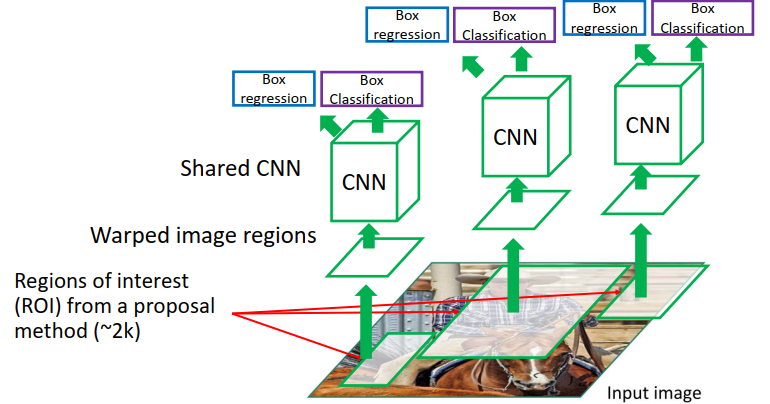
问题来了,虽然现在这种方式已经比暴力方法快很多了,但是还是很慢。因为几乎是把crop的图片丢尽了一整个网络2000次,一张图片的运行时间在47s(当时)这个量级。
思考如何改进:这2000张输入图片是有大量重叠的,所以说网络其实进行了很多重复的计算。
Fast RCNN
所以,为了避免上述这部分重复计算,Fast RCNN直接把原始图像先丢尽CNN得到一个feature map,再在feature map上做裁剪,这样就避免掉了大量重复的区域进入网络被重复计算。
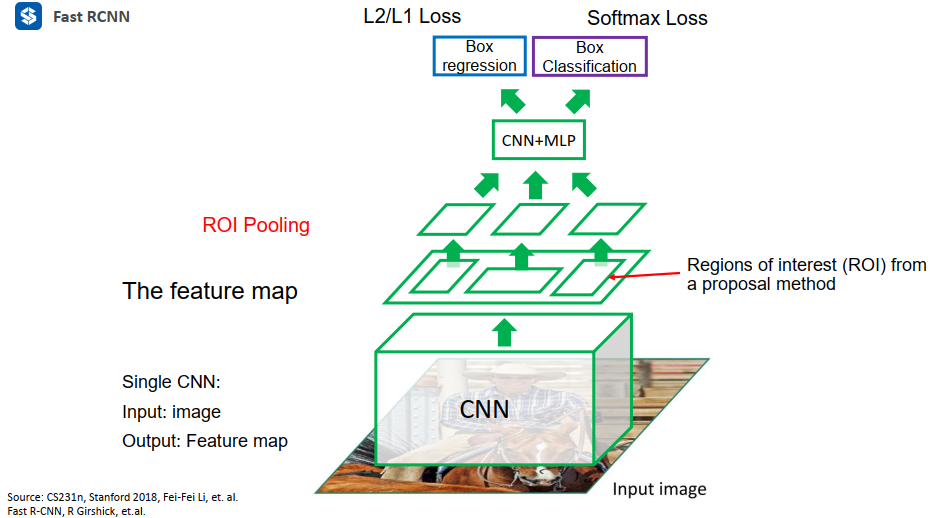
Q: feature map长宽与原图长宽不一致,那么如何做裁剪?以及裁剪出来后怎么变成大小一致?
A: 使用ROI Pooling
ROI Pooling
ROI Pooling过程示意如下:经过初始CNN后,经由3X640X480变成了512X20X15的feature map。
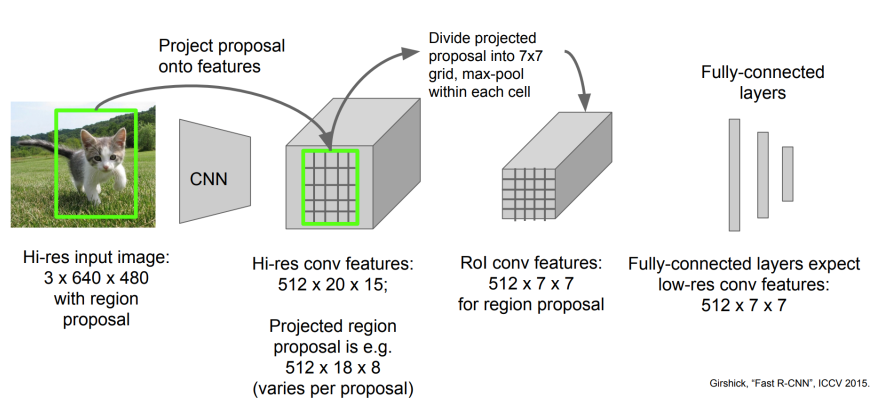
对feature map每一个通道:框等比例缩小后,框先停靠在就近像素点上(图右上红变黑),假如是2X2的max pool,那么每个方向上均分格子(整数),然后每个格子内做max pool。这就是ROI Pooling,实际上很简单。
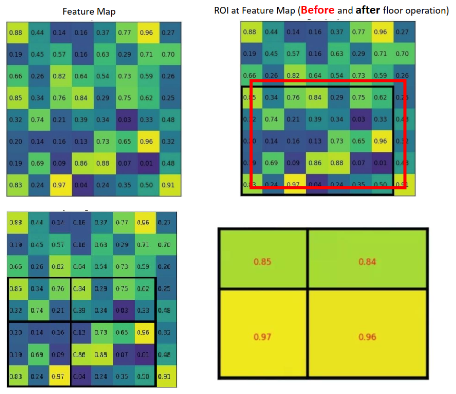
但是实际上由红框变黑框这样是有精度损失的,最后从feature map尺度变回原图时,这个放缩过程也将会带来一定的精度损失。所以提出了ROI Align。
ROI Align
ROI Align是在Mask RCNN内被提出的。核心的思路就是一切都采用浮点数来表示。如下图所示:要把本来大小是6.25 X 4.53的边框统一到3 X 3。
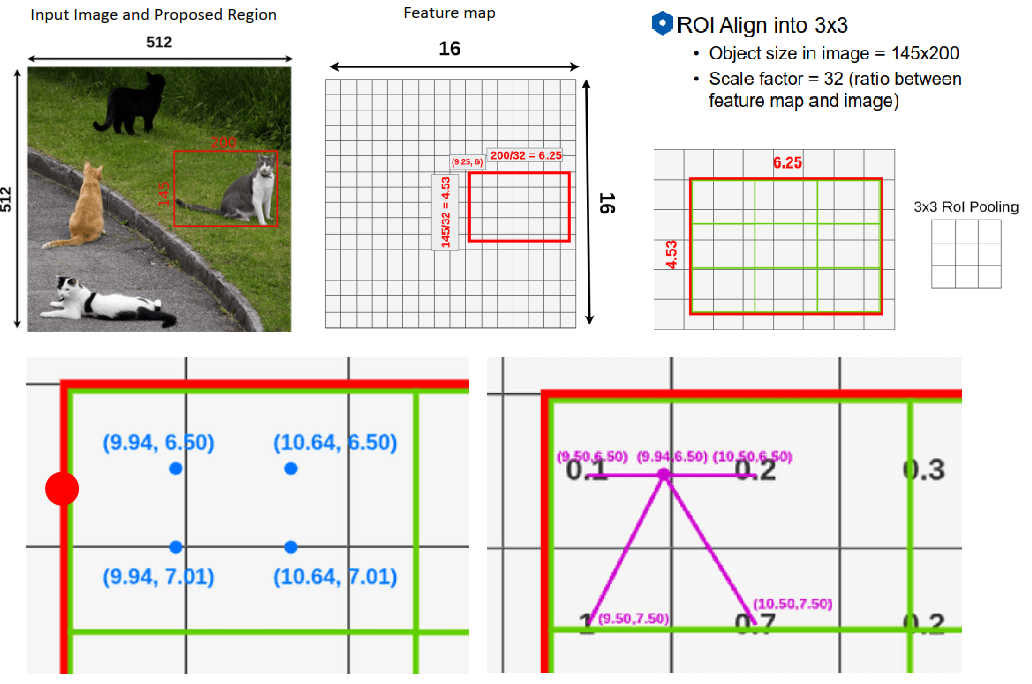
使用插值方法:图中每一个角点的位置都是已知的,如图左下,在绿框(最终要resize成的3 X 3)内生成4个点(长宽等分3份)。如右下角图所示,然后这四个点的每一个点的值又由相邻四个feature map的像素值插值而得。最终,在将四个点做一个max操作就能得到3 X 3中的一个像素的值了。
评价
总之,Fast RCNN首先将原图丢入卷积网络生成特征图,再在特征图上做region proposal,这样避免的不必要的重叠部分多次进入网络造成的重复计算,从而降低了时间开支。
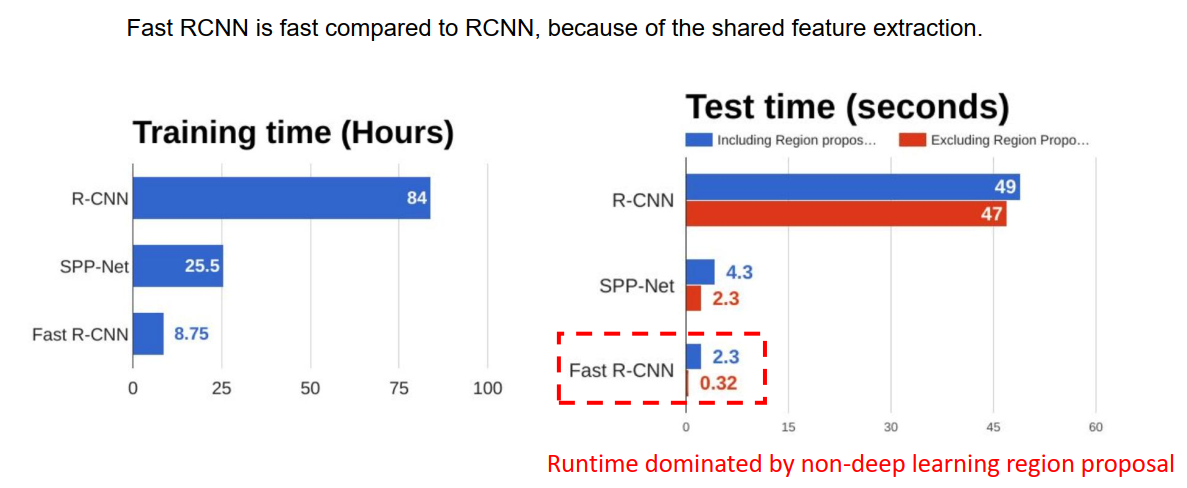
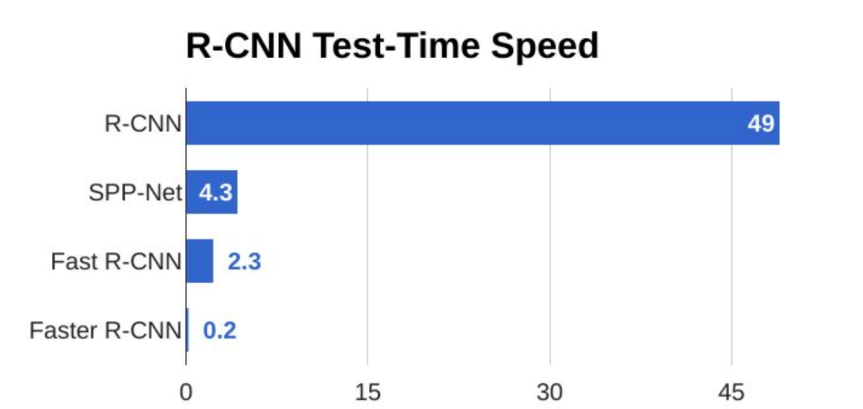
但是,从上图可以看出,Fast RCNN已经够快了。但现在Fast RCNN的时间开销主要来自于传统的region proposal方法,改进这个非传统方法就给整体算法带来较大时间上的性能提升。
所以,Faster RCNN应运而生,采用深度学习的方法代替传统方法。使用CNN做region proposal。
Faster RCNN
将fast rcnn中的传统region proposal方法替换为深度学习方法。叫做Region Proposal Network(RPN)。
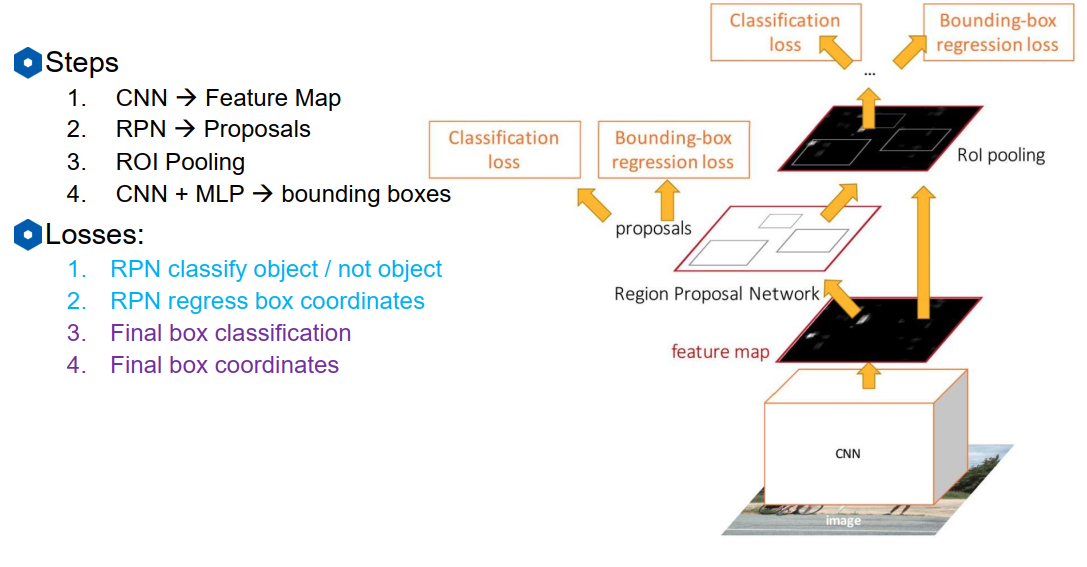
那么RPN又是如何在feature map生成候选框的呢?
Anchor概念
对feature map上每一个点(格子或像素)生成多个不同大小和尺度(下图三个颜色代表三个尺度)的"Anchor"作为初始候选,判断该anchor内是否包含有目标(包含有目标的概率和不包含目标的概率),包含则继续预测从当前anchor到ground truth的4个值的偏差。
下半图简单的把RPN当成是全连接网络举例,把C X anchor W X anchor H(加入是3X3 anchor)的向量拉成9C进入全连接网络输出为256维,然后外加两个做分类和回归的head。比如:分类问题用一个softmax来表示该anchor含有目标的概率和不包含目标的概率,所以输出的2*k个score,k为anchor数量。
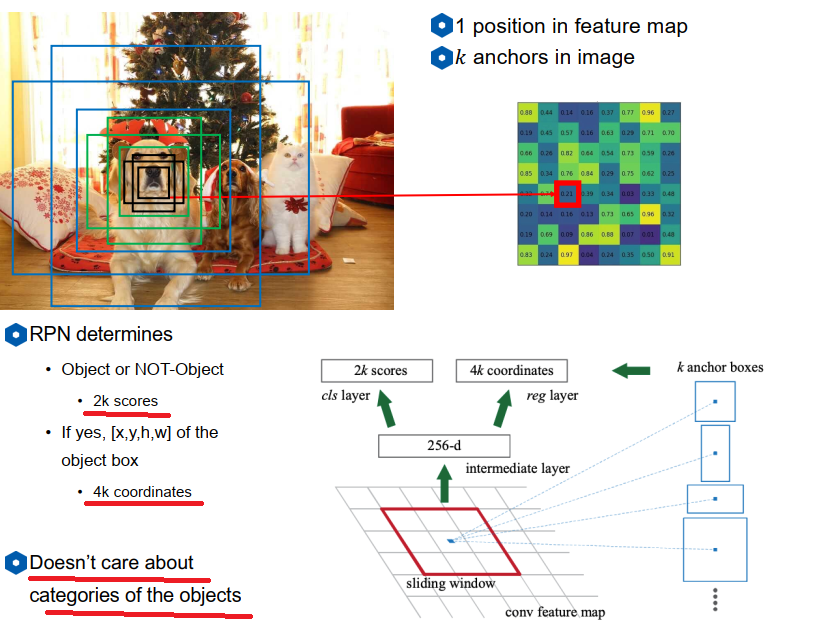
然后根据含有object的score排序,选择预测出的前300个region,即完成region proposal工作。如果总共是20X15规格的feature map,每个点6个anchor,那么初始的候选框其实也有2100种了(但是这2000个是以最简单的规则暴力生成的,不是复杂算法生成的,几乎不耗时)
Faster RCNN代码剖析
基于Reference里的几个链接,以及实际调试代码。
整体框架
首先看一下这个整体架构图。
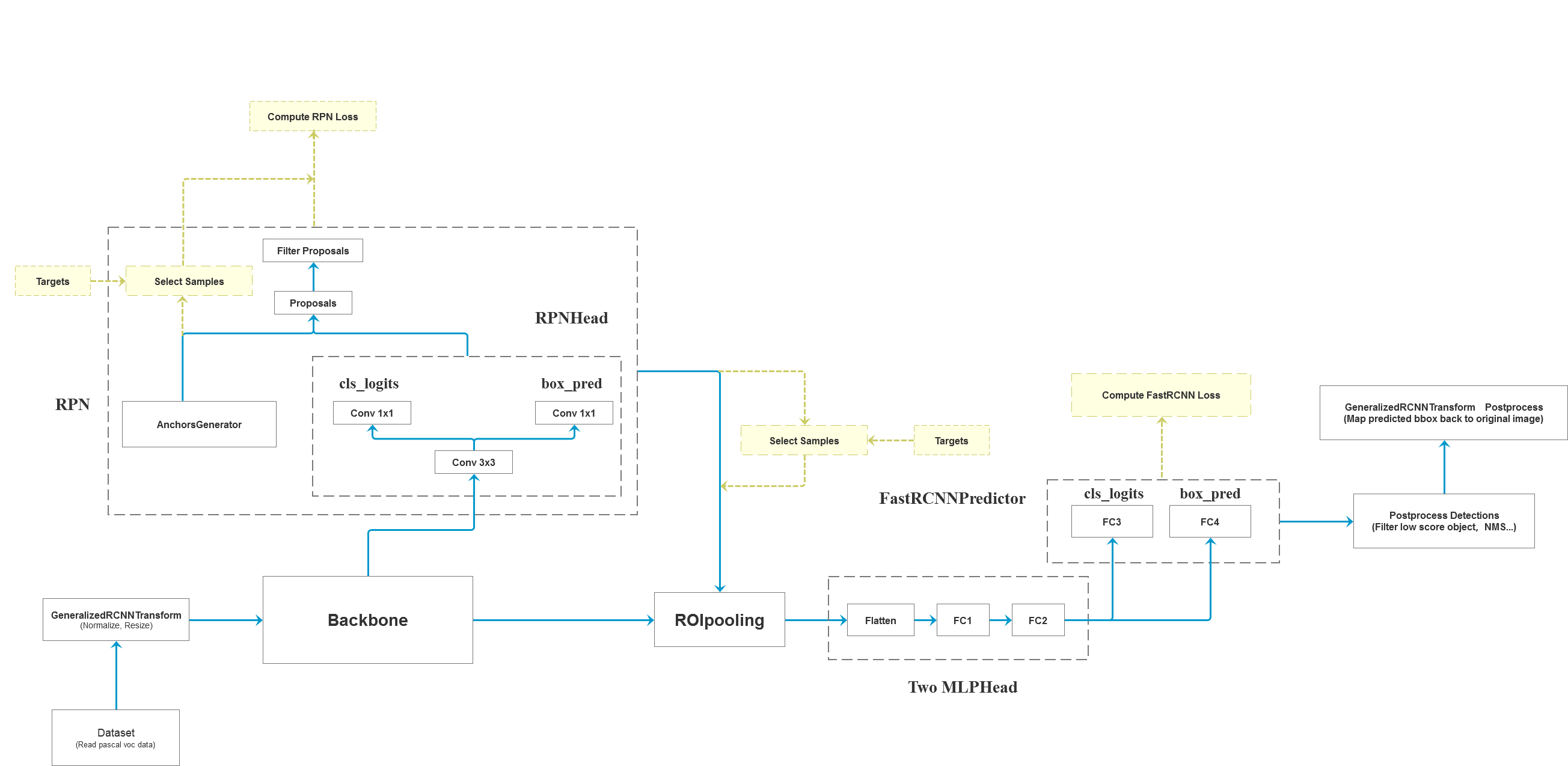
根据调试结构讲一下整个输入、输出。
首先,整个代码的流程是在generalized_rcnn.py里,这是一个基类,FasterRCNN(GeneralizedRCNN)将集成它,可以点进去看看forward函数明确框出代码的大结构。
self.transform = transform
self.backbone = backbone
self.rpn = rpn
self.roi_heads = roi_heads
继承时的默认参数都在这了
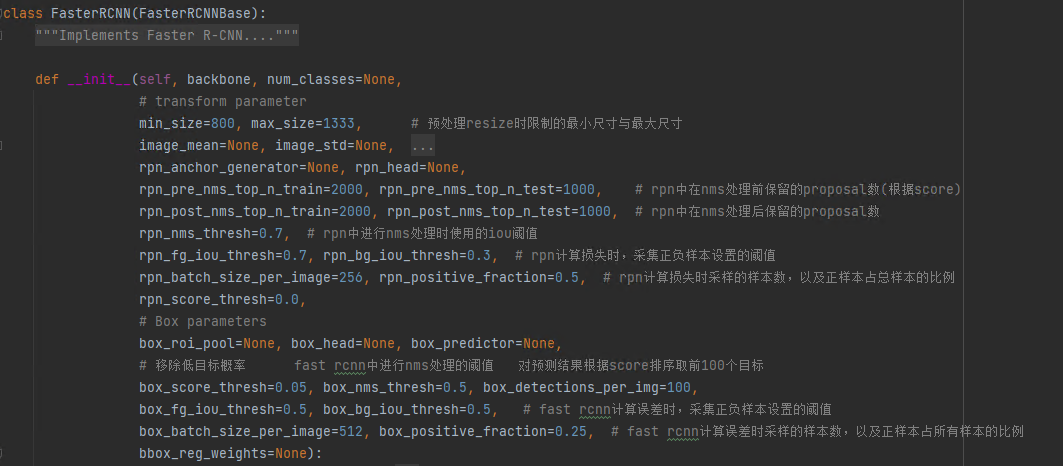
transform与Backbone
1.首先是transform与主干网络
-
如下图,假设batch size是4,图片大小是(375, 500),他会把图片resize到minsize=800,maxsize=1333。800这个尺度基本上是一定的,另外一个在根据大小一般在1000-1300漂浮,并记录下原始的尺寸(最终检测结果再恢复回去)
-
丢尽主干网络,原始的论文没有采用FPN,这里采用了FPN将输出5种大小尺度的特征图,通道数是256,批量大小是4。
RegionProposalNetwork
2.进入RPN,RegionProposalNetwork(时刻对照大图看)
注:RPN的最终目的是提供一推RegionProposal,相当于很多张在transform后的图像上的框。
RPN网络部分涉及到网络训练,所以训练和推理的过程不同,训练或多出一些求loss的步骤,会额外说明。
流程可见RegionProposalNetwork类的forward函数:
-
RPN HEAD,进行分类(有无)与框回归。
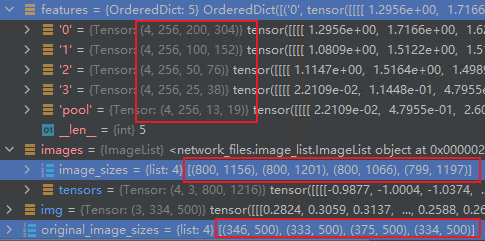
features = list(features.values()) # 5张特征图 objectness, pred_bbox_deltas = self.head(features)在所有的feature map丢尽卷积网络,预设的是每个特征图上的一点对应会生成3个Anchor,所以需要把(4,256,200,304)的map卷积成(4,3,200,304)的分类和(4,3X4,200,304)的框回归。
-
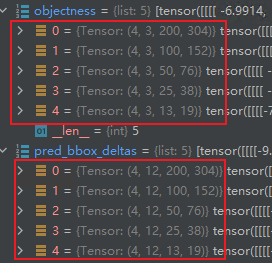
生成anchor,如上图所示,此时每张图片应生成的anchor的数量是3X(200X304+100X152+50X76+25X38+13X19)=242991,anchor的尺度也是在“原图”上生成的。将HEAD输出的4X242991个box作为原始的proposal。
-
接下来对proposal进行过滤。
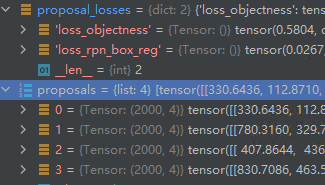
boxes, scores = self.filter_proposals(proposals, objectness, images.image_sizes, num_anchors_per_level)对于每一张输入图片,首先根据HEAD输出的objectness,在其每张特征图上选取rpn_pre_nms_top_n_train个即头2000个box(Test是1000),由于最小的特征图只有13X19X3=741个proposal,所以总共在pre_nms阶段选出了8741个proposal,再对舍去小面积box,根据阈值移除score小的proposal,再根据超参数rpn_nms_thresh=0.7进行NMS(比如NMS后可能还剩下3200个),最后选取rpn_post_nms_top_n_train=2000选取score前2000的proposal。一张图片最终生成2000个proposal,4张即8000个。
如果是训练阶段,还要进行正负样本的判断并计算分类与回归的loss。
-
计算每个anchor是正样本还是负样本,并计算box的偏移量。
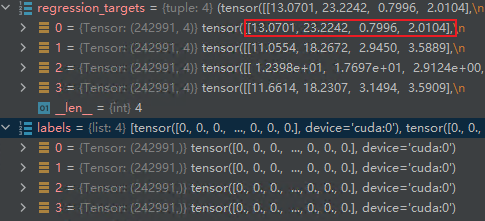
labels, matched_gt_boxes = self.assign_targets_to_anchors(anchors, targets) regression_targets = self.box_coder.encode(matched_gt_boxes, anchors) # 结合anchors以及对应的gt,计算regression参数根据超参数rpn_fg_iou_thresh=0.7,如果anchor与gt_boxes的iou大于0.7则是前景,根据rpn_bg_iou_thresh=0.3,小于0.3则是负样本。label的数量还是跟每张图anchor的总数量相同。
-
选择预设数量的正、负样本计算loss。
loss_objectness, loss_rpn_box_reg = self.compute_loss(objectness, pred_bbox_deltas, labels, regression_targets) # self.compute_loss 函数内 sampled_pos_inds, sampled_neg_inds = self.fg_bg_sampler(labels)根据rpn_batch_size_per_image=256, rpn_positive_fraction=0.5,采样正负样本,即每张图像随机采样(可以进代码看)128个正样本,128个负样本;4张图的话就是使用总共4X256=1024个样本计算loss。**注:**有可能一张图的正样本数量到不了128,那么就用负样本来补齐(如下,4张图才86个正样本,跑了下代码,感觉大多数时候都只有100个左右的正样本)。

ROI HEAD
每张图得到2000个proposal后,进入ROI HEAD
ROI HEAD的训练和测试依然是有差异的,训练阶段的话是想得到比较好的loss所以选择部分proposal进行训练,不需要得到结果;而测试阶段不计算loss,直接把全部proposal丢进网络得出分类和回归结果,再进行包含有NMS的后处理得到最终结果。
所以,以下完全分为train和Test来说:(对比RPN网络,不管是train还是test都是要得出proposal的,所以train比test前部分总体相同,train多出一个计算loss)
| train:主要为了计算loss | test:主要为了得出最终结果 |
|---|---|
| 1.选择出部分proposal以及对应的label | 1.不操作,使用全部proposal |
| 2.ROI Align | 2.ROI Align |
| 3.丢尽网络得出预测的分类(目标种类)和框回归结果 | 3.丢尽网络得出预测的分类(目标种类)和框回归结果 |
| 4.计算loss | 4.包含NMS的后处理得出结果 |
train:
- 得出proposal对应的label,并采样正负样本。
# 得到所有proposal的label
matched_idxs, labels = self.assign_targets_to_proposals(proposals, gt_boxes, gt_labels)
# 前景与背景的IOU
# box_fg_iou_thresh=0.5, box_bg_iou_thresh=0.5,
# 每张图从2000个采样至512个proposal,并且正样本最高占有1/4(因为大部分时候正样本数量不足)
box_batch_size_per_image=512, box_positive_fraction=0.25,
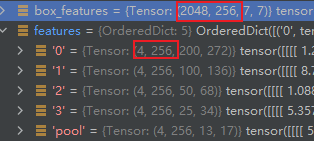
- ROI Align。ROI的输入是proposal以及feature maps,根据proposal把特征图裁剪到7X7。注意观察下图中feature map变到box_features的变化,批量本来是4,然后每张图512个proposal,所以第一维度变成了4X512=2048,通道数不变,HXW变成了7X7
-
丢尽网络分类与回归。
# 拉成一维并进入两层全连接层 box_features = self.box_head(box_features) # 分类、回归 class_logits, box_regression = self.box_predictor(box_features) -
计算loss。两个loss,没什么好说的。加上RPN反馈的loss,总共就是4个loss,调试的这份代码是直接把所有loss加到一起进行梯度下降的。
test:
-
test阶段只会从RPN得到rpn_post_nms_top_n_test=1000个proposal!
-
ROI Align,不具体说了,由于单图proposal有1000个,所以box_features应该是(4000,256,7,7)
-
丢尽网络分类与回归。跟上面一样。
-
后处理
boxes, scores, labels = self.postprocess_detections(class_logits, box_regression, proposals, image_shapes) """ 对网络的预测数据进行后处理,包括 (1)根据proposal以及预测的回归参数计算出最终bbox坐标 (2)对预测类别结果进行softmax处理 (3)裁剪预测的boxes信息,将越界的坐标调整到图片边界上 (4)移除所有背景信息 (5)移除低概率目标 box_score_thresh=0.05 (6)移除小尺寸目标 (7)执行nms处理,并按scores进行排序 box_nms_thresh=0.5 (8)根据scores排序返回前topk个目标 box_detections_per_img=100 """
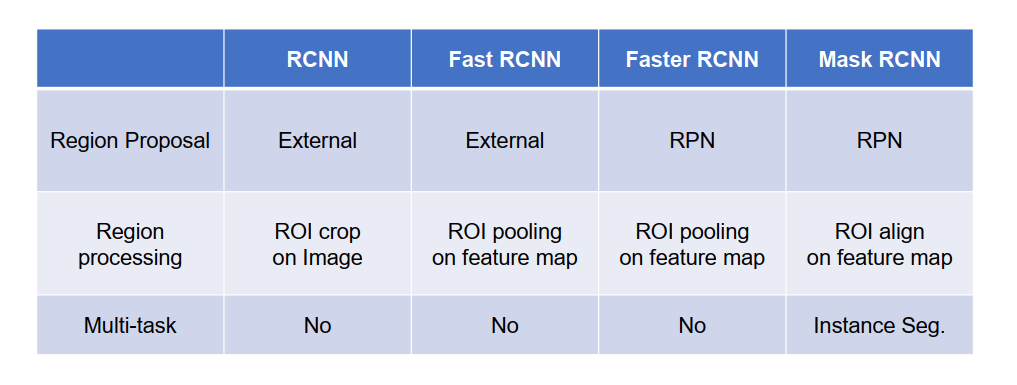
家族对比
改进方向
速度比对
need two stage?
是否可以不要第二阶段?
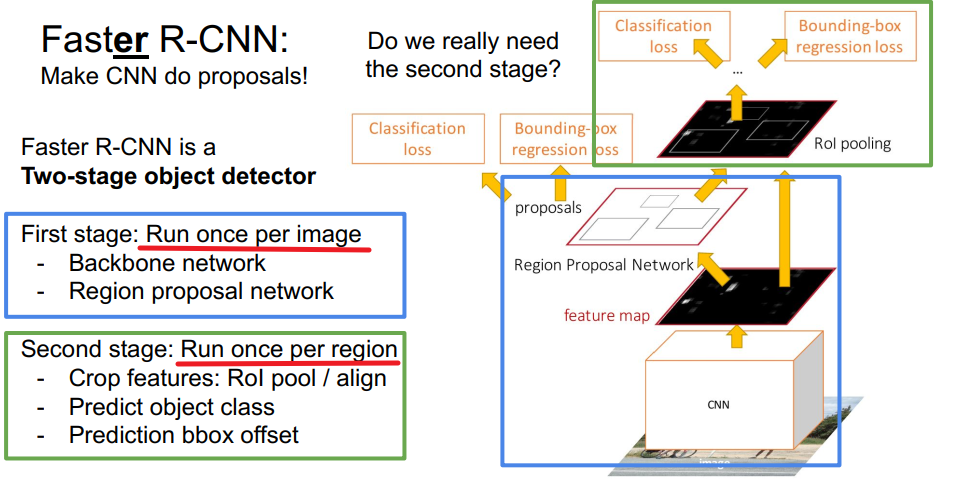
one stage
RPN HEAD和ROI HEAD完成的工作类似,所以现在网上教程一般都是先从one stage入手,再讲two stage。但是先学two stage家族有一个好处就是:可以清晰的看出物体检测这一任务从传统方法到深度学习方法的过渡,思路和逻辑都很明确。